SQL(Structured Query Language)은 데이터베이스와 상호 작용하는데 사용되는 언어로, 데이터를 조회/추가/수정/삭제하는데에 사용됨.
▶ SQL 작성 절차
- 요구사항 이해 :
- 먼저 데이터베이스와 상호 작용해야 하는 작업의 요구사항을 명확하게 이해해야함. 이 작업이 어떤 데이터를 필요로 하는지, 어떤 조건이 적용되는지, 결과 데이터는 어떤 형식으로 나와야 하는지 등을 파악해야함. - 데이터베이스 접속 :
- SQL 작성을 위해 DB에 접속해야함. 이를 위해 DBMS(= 데이터베이스 관리 시스템)에 대한 연결을 설정하고, 인증 및 권한 확인 등의 단계를 수행함. - SQL 쿼리 작성 :
- 요구 사항에 기반하여 SQL 쿼리 작성. 쿼리 유형은 크게 SELECT / INSERT / UPDATE / DELETE로 나뉨.
- 필요한 테이블 및 열을 명시하고, 조건을 지정하여 원하는 결과를 얻을 수 있도록 작성
- SQL 문은 대소문자를 구별하지 않으며 한 줄 또는 여러 줄에 입력 가능.
- 일반적으로 키워드는 대문자로, 테이블 명이나 열 이름 같은 단어들은 소문자로 입력하는것이 권장됨.
- 가장 최근의 명령어 한개가 SQL buffer에 저장됨.
- SQL 문 마지막 절의 끝에 ';'를 기술하여 명령의 끝을 표시. - 쿼리 테스트 :
- 작성한 SQL 쿼리 테스트. DB에서 쿼리 실행 후 동작 및 결과 확인. - 오류 확인 및 수정 :
- 쿼리 실행 중에 오류가 발생하면 오류 메시지를 분석하고 수정.
- 오류에는 문법 오류, 데이터 오류, 권한 부족 등이 있음 - 최적화 (선택사항) :
- 대용량 DB에서 작업할때, 쿼리의 성능을 최적화할 필요가 있을 수 있음. 인덱스를 추가하거나 쿼리를 재작성하여 성능을 향상 시킬 수 있음. - 실행 :
- 쿼리가 테스트를 통과하면 실제 운영 환경에서 실행.
- DB에 영향을 미치는 작업이므로 주의 깊게 실행해야함. - 결과 확인 :
- 예상한 결과인지 쿼리 실행 결과 확인. - 문서화 (선택사항) :
- SQL 쿼리와 작업 내용을 문서화하여 나중에 작업을 재검토하거나 다른 개발자와 공유할 수 있도록 함.
▷ SELECT 문법
- DB에 저장된 데이터를 조회하는데 사용.
SELECT [DISTINCT] {*, column [alias], ...}
FROM table명
[WHERE condition]
[ORDER BY {column, expression} [ASC | DESC]];
⦁ DISTINCT = 중복되는 행 제거
⦁ * = 테이블의 모든 column 출력
⦁ alias = 해당 column에 대해서 별명 부여 (as라는 키워드 사용, 생략 가능)
⦁ WHERE = 조건을 만족하는 행들만 검색
⦁ condition = column, 표현식, 상수 및 비교 연산자
⦁ ORDER BY = 질의 결과 정렬을 위한 옵션 (ASC=오름차순/DESC=내림차순)
> WHERE 절에 사용될 수 있는 연산자
| BETWEEN a AND b | a와 b 사이의 데이터를 출력 (a, b 값 포함) |
| NOT BETWEEN a AND b | a와 b 사이에 있지않은 데이터 출력. (a, b 값 포함 x) |
| IN (list) | list의 값 중 어느 하나와 일치하는 데이터를 출력 |
| NOT IN (list) | list의 값과 일치하지 않는 데이터를 출력 |
| LIKE | 문자 형태로 일치하는 데이터를 출력 (%, _사용) |
| NOT LIKE | 문자 형태와 일치하지 않는 데이터를 출력 |
| IS NULL | NULL 값을 가진 데이터를 출력 |
| IS NOT NULL | NULL 값을 갖지 않는 데이터를 출력 |
> LIKE 연산자
- 검색 String 값에 대한 와일드 카드 검색을 위해서 사용.
- '%' = 여러 개의 문자열을 나타내는 와일드 카드
- '_' = 단 하나의 문자를 나타내는 와일드 카드
- ESCAPE = 와일드 카드 문자를 일반문자처럼 사용하고 싶은 경우 사용 (ex. WHERE name LIKE '%a\_y%' ESCAPE '\')
- LIKE 연산자는 대소문자를 구분하지만 UPPER() 함수를 이용해 대소문자 구분없이 출력 가능. (함수기반 인덱스 사용에 따른 인덱스 성능문제가 발생할 수 있음)
| LIKE 'A%' | 'A'로 시작하는 데이터들만 검색 |
| LIKE '%A' | 'A'로 끝나는 데이터들만 검색 |
| LIKE '%LION%' | 'LION' 문자가 있는 데이터들만 검색 |
| LIKE '%L%N%' | 'L' 문자와 'N' 문자가 있는 데이터들만 검색 |
| LIKE '_A%' | 'A' 문자가 두번째 위치한 데이터들만 검색 |
> LIMIT 연산자
- 검색 결과의 일부분만 반환하려고 할때, LIMIT 사용 가능
LIMIT [start_index, ] row_count;↳ start_index = 검색하고자 하는 시작 행의 위치. 생략시 첫번째 행부터 검색
↳ row_count = 검색하고자 하는 행의 개수 지정.
▷ SELECT 기능
⦁ SELECTION : 테이블에서 데이터를 검색할때 반환될 행을 선택할 수 있으며, SELECT 시 다양한 조건을 사용하여 검색하고자 하는 행을 선택적으로 제한할 수 있음.

⦁ PROJECTION : 테이블에서 데이터를 검색할때 반환될 열을 선택할 수 있음.
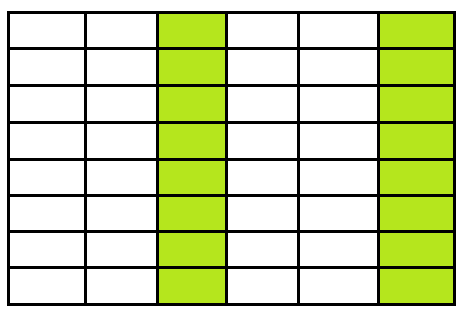
⦁ JOIN : 서로 다른 테이블을 연결하여 한번에 데이터를 함께 검색할 수 있음.
- 2개 이상의 Table을 조합해 새로운 Table을 만듦

| 종류 | 이미지 | 설명 |
| INNER JOIN |  |
두 집합의 "교집합" |
| CROSS JOIN |  |
두 집합의 "곱집합" (요소끼리 곱함) |
| FULL [OUTER] JOIN |  |
양쪽 모두 데이터를 붙임 |
| LEFT [OUTER] JOIN |  |
왼쪽 기준으로 붙임 |
| RIGHT [OUTER] JOIN |  |
오른쪽 기준으로 붙임 |
▶ DML (Data Manipulation Language)
▷ INSERT
- 테이블 안에 데이터 삽입
INSERT INTO table명(column1, column2, ...)
VALUES (데이터, '문자열데이터', ...);INSERT INTO table명(column1, column2, ...)
SELECT column1, column2, ...
FROM other_table명
WHERE 조건;- 실제 데이터는 VALUES 괄호 안에 입력하고 문자열은 단일 따옴표(' ')로 감싼다.
- 각각의 데이터 구분은 ','로 한다.
- 테이블 이름 옆에 괄호 생략시에는 자동으로 모든 컬럼을 VALUES() 안에 입력시킨다.
▷ UPDATE
- 테이블 안의 데이터 수정
UPDATE table명
SET column1 = 값(고칠내용), column2 = ...
WHERE 조건;
▷ DELETE
- 사용하지 않는 데이터 삭제
DELETE FROM table명
WHERE 조건;
▶ 데이터 모델링
- 데이터는 테이블에 저장되고, 테이블은 데이터 모델을 기반으로 하여 생성함.
> 모델링의 정의
- 3차원의 현실 세계를 단순화하여 표현하는 것을 말함 (단순화)
- 현실 세계를 추상화하여 그 구조를 표현함 (추상화)
- 현실 세계에 존재하는 사물이나 사건에 관한 관점 및 양상을 연관된 주체를 위해 명확하게 하는 것. (명확화)
| 단순화 | 복잡한 현실 세계를 서로가 약속한 규약을 준수하는 표기법이나 언어로 표현 |
| 추상화 | 복잡한 현실 세계를 일정한 형식에 맞게 표현 |
| 명확화 | 복잡한 현실 세계를 명확하게 기술 모델을 보는 여러 관계자가 이해하기 쉽게 애매모호함을 제거하여 표현 |
> 모델링의 3가지 관점
| 데이터 관점 | 비즈니스와 관련된 데이터는 무엇인지 또는 데이터 간의 관계는 무엇인지에 대한 관점 |
| 프로세스 관점 | 해당 비즈니스로 인해 일어나는 일은 어떤 일인지에 대한 관점 |
| 상관 관점 | 데이터 관점과 프로세스 관점 간에 서로 어떠한 영향을 받는지에 대한 관점 |
> 데이터 모델링 정의
- 현실 세계의 비즈니스를 IT 시스템으로 구현하기 위해 데이터 관점으로 업무를 분석하는 기법
- 현실 세계의 비즈니스를 약속된 표기법으로 표현하는 과정
- IT 시스템의 근간이 되는 DB를 구축하기 위한 분석 및 설계의 과정
- 데이터 모델링 과정을 통해 데이터 모델을 도출하며, 데이터 모델은 다양한 기능을 제공함.
↳ 데이터 모델의 기능
| 가시화 | IT 시스템의 모습을 가시화하는 기능 제공 |
| 명세화 | IT 시스템의 구조와 발생하는 동작 명세화 |
| 구조화된 틀 제공 | IT 시스템을 구현하기 위해 필요한 구조화된 틀 제공 |
| 문서화 | IT 시스템 구축시 산출물로 사용되는 문서 제공 |
| 다양한 관점 제공 | 다른 영역의 세부사항을 숨김으로써 다양한 영역에 집중할 수 있는 관점 제공 |
| 상세 수준의 표현 방법 제공 | 원하는 목표에 따라 구체화된 상세 수준의 표현 방법 제공 |
> 데이터 모델이 중요한 이유
- 파급효과(Leverage) : 데이터 설계 과정에서 비효율적인 데이터 설계 및 업무 요건을 충족하지 못하는 데이터 설계를 한다면 개발/테스트/오픈/운영의 전 과정에 걸쳐서 엄청난 비용이 발생할 수 있음
- 복잡한 정보 요구사항의 간결한 표현(Conciseness) : 좋은 데이터 모델 설계를 통해 IT 시스템에서 구현해야 할 정보 요구사항을 명확하고 간결하게 표현할 수 있음
- 데이터 품질(Data Quality) : 데이터 모델의 잘못된 설계로 인해 데이터 중복, 비유연성, 비일관성이 발생할 수 있음. 이로 인해 데이터 품질 저하될 수 있음.
> 데이터 모델링의 3단계
| 개념적 데이터 모델링 | IT 시스템에서 구현하고자 하는 대상에 대해 포괄적 수준의 데이터 모델링을 진행 전사적 데이터 모델링 시 많이 사용하는 단계 |
| 논리적 데이터 모델링 | IT 시스템에서 구현하고자 하는 비즈니스를 만족하기 위한 기본키, 속성, 관계, 외래키 등을 정확하게 표현하는 단계 |
| 물리적 데이터 모델링 | 논리 데이터 모델을 기반으로 실제 물리 DB 구축을 위해 성능, 저장공간 등의 물리적인 특성을 고려하여 설계하는 단계 |
> 데이터 독립성
- 데이터 독립성은 하위 단계의 데이터 구조가 변경되더라도 상위 단계에는 영향을 미치지 않는 속성을 말함.
- 데이터 독립성은 보유한 데이터의 복잡도를 낮추고 중복된 데이터를 줄여서 시간의 흐름에 따라 증가하는 IT 시스템의 유지보수 비용을 절감하는데 목적이 있음
- 사용자의 요구사항은 지속적으로 신규/수정/삭제가 발생하고 있으며, 그에 따른 화면과 물리 DB간 서로 독립성을 유지하기 위해 데이터 독립성이라는 개념이 출현함.
> 데이터베이스 3단계 구조
- ANSI/SPARC 3단계 구성의 데이터 독립성 모델은 외부 단계와 개념적 단계, 내부적 단계로 구성된 서로 간섭되지 않는 모델을 제시함.
| 외부 스키마 (External Schema) |
각각의 사용자가 보는 DB 스키마 개인 사용자 혹은 응용 프로그램 개발자가 접근하는 DB 스키마 |
사용자 관점 |
| 개념 스키마 (Conceptual Schema) |
모든 사용자의 관점을 하나로 통합한 비즈니스 전체의 DB를 기술한 스키마 응용 프로그램 및 사용자들이 필요한 데이터를 통합한 전체 DB를 기술한 것으로, 실제 DB에 저장되는 데이터와 응용 프로그램 및 사용자들 간의 관계를 표현하는 스키마 |
통합 관점 |
| 내부 스키마 (Internal Schema) |
DB가 물리적으로 저장된 형식을 표현한 스키마 물리적 하드웨어 장치에 데이터가 실제로 저장되는 방법을 표현한 스키마 |
물리적 관점 |
> 데이터베이스 3단계 구조에서의 2가지 데이터 독립성
| 논리적 데이터 독립성 | 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원하는 것을 뜻함 논리적 구조가 변경되어도 응용 프로그램에 영향을 미치지 않음 |
사용자 특성에 맞는 변경이 가능함 통합 구조의 변경이 가능함 |
| 물리적 데이터 독립성 | 내부 스키마가 변경되어도 외부/개념 스키마는 영향을 받지 않도록 지원하는 것을 뜻함 저장 장치의 구조 변경은 응용 프로그램/개념 스키마에 영향을 미치지 않음 |
물리 구조에 영향 없이 개념 구조의 변경이 가능함 개념 구조에 영향 없이 물리 구조의 변경이 가능함 |
> 데이터 모델링 용어
| 개념 | 복수 / 집합 개념 타입 / 클래스 | 개별 / 단수 개념 어커런스 / 인스턴스 |
| Things (어떤 것) | 엔티티 타입 (Entity Type) | 엔티티 (Entity) |
| 엔티티 (Entity) | 인스턴스 (Instance) 어커런스 (Occurrence) |
|
| Association between Things (어떤 것 간의 연관) | 관계 (Relationship) | 페어링 (Pairing) |
| Characteristic of a Thing (어떤 것의 성격) | 속성 (Attribute) | 속성값 (Attribute Value) |
↳ ex) - 직원 엔티티 내에 '홍길동'이라는 직원이 추가될 경우, '홍길동' 직원을 인스턴스/어커런스라고 부름.
- 직원 엔티티와 급여 엔티티는 "직원은 급여를 지급받는다"라는 관계를 가짐.
- 관계에 포함된 개별 연관성을 페어링이라고 함.
- 직원 엔티티에서 직원명 같은 것을 속성이라고 하며, '홍길동'과 같은 속성에 대한 값들은 속성값이라고 함.
▷ ERD (Entity Relationship Diagram)
- ERD는 데이터 모델을 표기하는 표기법.
- ERD를 그린다는 것은 데이터 모델링 작업을 하는 것과 같음
- ERD를 그리는 순서 : 엔티티를 그린 후 그 엔티티를 적절한 위치에 배치함. 각 엔티티 간의 관계를 설정하고 관계명을 기술함. 관계의 참여도를 기술하고 필수 여부를 기술하면 완성됨.
> 좋은 데이터 모델의 요소
- 완전성 : 업무에 필요한 데이터가 모두 정의되어야 함
- 중복 배제 : 동일한 사실은 단 한번만 저장해야 함
- 업무 규칙 : 데이터 모델 분석만으로도 비즈니스 로직이 이해되어야 함
- 데이터 재사용 : 데이터 통합성과 독립성을 고려하여 재사용이 가능해야 함
- 의사소통 : 데이터 모델을 보고 이해 당사자들끼리 의사소통이 이루어질 수 있어야 함
- 통합성 : 동일한 데이터는 유일하게 정의해서 다른 영역에서 참조해야 함.
▶ 엔티티 (Entity)
- 엔티티란 비즈니스 관점에서 IT 시스템을 통해 저장 및 관리해야 하는 집합적인 어떤 것.
- 엔티티는 사람, 사물, 사건, 개념 등의 명사에 해당함
- 하나의 엔티티는 여러개의 인스턴스를 가질 수 있으므로 엔티티는 인스턴스의 집합이라고 할 수 있음
> 엔티티의 특징
- 비즈니스 요구 조건 만족을 위해 반드시 필요하고, 저장 및 관리하고자 하는 정보여야 함. (업무에서 필요로 하는 정보)
- 유일한 식별자에 의해 식별이 가능해야 함. 즉, 집합 내에서 단 1건을 짚어낼 수 있어야 함. (식별가능해야 함)
- 영속적으로 존재하는 인스턴스의 집합이어야 함. (인스턴스의 집합)
- 엔티티는 비즈니스 프로세스에 의해 반드시 이용되어야 함. (업무 프로세스에 의해 이용)
- 엔티티는 반드시 속성을 가지고 있어야 함. (속성을 포함)
- 엔티티는 다른 엔티티와 최소 1개 이상의 관계가 있어야 함. (관계의 존재)
> 엔티티의 분류
- 엔티티는 크게 유무 형에 따른 분류와 발생시점에 따른 분류로 구분할 수 있음.
- 유무형에 따른 분류로는 유형 엔티티, 개념 엔티티, 사건 엔티티가 있음.
- 발생시점에 따른 분류로는 기본 엔티티, 중심 엔티티, 행위 엔티티가 있음.
> 엔티티의 명명 규칙
- 가능한 업무 담당자들이 사용하는 용어 사용
- 가능하면 약어를 사용하지 않음
- 엔티티는 단수명사여야 함
- 엔티티의 이름은 해당 모델 내에서 유일한 이름이어야 함.
- 엔티티의 생성 의미에 맞게 이름 부여
▶ 속성 (Attribute)
- 속성은 비즈니스에서 필요로 하며, 인스턴스에서 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위를 말함.
- 엔티티에 대한 설명이며 인스턴스의 구성 요소가 됨.
- 속성은 엔티티에 대한 자세하고 구체적인 정보를 나타내며, 각각의 속성은 구체적인 값을 갖게 됨.
↳ ex) 지하철역(엔티티)은 여러 개의 역(인스턴스)이 있고, 지하철역에 대한 정보는 노선명과 역명(속성)이 있으며, '경의중앙'선의 '신촌'역(속성값)이 있음.
- 1개의 엔티티는 여러 개의 인스턴스를 가질 수 있고 하나의 인스턴스는 여러 개의 속성을 가짐.
> 속성의 표기법
- "#"을 붙여 식별자임을 표시
- "*"을 붙여 필수 값임을 표시
- "○"를 붙여 선택값임을 표시
> 속성의 특징
- 엔티티와 마찬가지로 반드시 비즈니스에서 필요로 하고 IT 시스템에서 저장 및 관리하고자 하는 정보여야 함
- 정규화 이론에 따라 속성이 속해 있는 엔티티의 주식별자에 함수적 종속성을 가져야 함
- 하나의 속성에는 1개의 값만을 가짐. 하나의 속성에 여러개의 값이 있는 다중 값일 경우 별도의 엔티티를 이용하여 분리.
> 속성의 분류
☞ 특성에 따른 분류
| 기본 속성 (Basic Attribute) |
비즈니스 분석을 통해 도출된 속성 (ex. 상가 엔티티의 상호명 속성) |
| 설계 속성 (Designed Attribute) |
비즈니스 분석을 통해 도출된 것은 아니지만 데이터 모델 설계를 하면서 도출하는 속성 (ex. 상가 엔티티의 표준산업분류코드 속성) |
| 파생 속성 (Derived Attribute) |
다른 속성에 의해서 계산이나 변형이 되어 생성되는 속성 (ex. 상가 엔티티의 주소정보를 기반으로 위도, 경도 속성의 값을 구한다고 가정시, 위도 경도 속성은 파생 속성) |
☞ 엔티티 구성 방식에 따른 분류
| PK (Primary Key) 속성 | 엔티티에서 단 하나의 인스턴스를 식별할 수 있는 속성 |
| FK (Foreign Key) 속성 | 타 엔티티와의 관계를 통해 포함된 속성 |
| 일반 속성 | 엔티티 내에 존재하면서 PK 혹은 FK 속성이 아닌 속성 |
▶ 도메인 (Domain)
- 속성이 가질 수 있는 값의 범위 및 유형을 도메인이라고 함.
- 학생 엔티티의 학점 속성의 도메인은 0.0 ~ 4.5의 범위를 갖는 실수 값으로 정의 가능.
- 학생 엔티티의 핸드폰번호 속성은 길이가 20자리 이내인 문자열로 정의가능
- 각 속성의 속성값은 정의된 도메인 이외의 값을 가질 수 없음.
▶ 관계 (Relationship)
- 관계는 엔티티끼리 상호 연관성이 있는 상태를 의미함.
- 데이터 모델 내에 존재하는 엔티티 간 논리적인 연관성을 의미함.
> 관계의 페어링 (Relationship Pairing)
- 관계는 엔티티 안에 인스턴스가 개별적으로 관계를 가지는 것(페어링)이고 이것의 집합을 관계로 표현하는 것.
- 개별 인스턴스가 각각 다른 종류의 관계를 가지고 있다면 두 엔티티 사이에 2개 이상의 관계가 형성될 수 있음.
> 관계 선택사양 (Optionality)
- 관계 선택사양에는 필수참여관계와 선택참여관계가 있음.
> 관계 정의시 체크 사항
- 2개의 엔티티 사이에 관심있는 연관 규칙이 존재하는가?
- 2개의 엔티티 사이에 정보의 조합이 발생되는가?
- 업무기술서, 장표에 관계연결에 대한 규칙이 서술되어 있는가?
- 업무기술서, 장표에 관계연결을 가능하게 하는 동사가 있는가?
▶식별자 (Identifier)
- 엔티티라는 인스턴스들의 집합에서 단 하나의 인스턴스를 구별해 낼 수 있는 논리적인 이름이 필요하며 이러한 구분자를 식별자라고 함. (엔티티의 각 인스턴스를 개별적으로 식별하기 위해 사용되는 하나의 속성 혹은 속성들의 조합)
- 식별자는 주 식별자에 의해 엔티티 내의 모든 인스턴스들이 유일하게 구분되어야 하고(유일성), 주 식별자를 구성하는 속성의 수는 유일성을 만족하는 최소의 수가 되어야 함(최소성).
- 지정된 주 식별자의 값은 자주 변하지 않는 것이어야 하고(불변성), 주 식별자가 지정되면 반드시 값을 포함해야 함.(존재성), 주 식별자는 NULL을 허용하지 않음.
> 식별자의 분류
| 대표성 여부 | 주 식별자 | 엔티티 내에서 각각의 행을 구분할 수 있는 구분자. 다른 엔티티와 참조관계를 가질때 연결할 수 있는 식별자 |
사원번호, 고객번호 |
| 보조 식별자 | 엔티티 내에서 각각의 행을 구분할 수 있음. 하지만 주 식별자가 아니라서 대표성을 가지지 못하므로 다른 엔티티와 참조관계를 가질때 연결할 수는 없음 |
주민등록번호 | |
| 스스로 생성 여부 | 내부 식별자 | 엔티티 내부에서 스스로 만들어지는 식별자 | 고객번호 |
| 외부 식별자 | 다른 엔티티와의 관계를 통해 다른 엔티티로부터 받아오는 식별자 | 주문 엔티티의 고객번호 | |
| 속성의 수 | 단일 식별자 | 하나의 속성으로 구성된 식별자 | 고객 엔티티의 고객번호 |
| 복합 식별자 | 둘 이상의 속성으로 구성된 식별자 | 주문 상세 엔티티의 주문번호 & 상세 순번 | |
| 대체 여부 | 본질 식별자 | 비즈니스에 의해 만들어지는 식별자 | 고객번호 |
| 인조 식별자 | 비즈니스적으로 만들어지지는 않지만, 본질 식별자가 복잡한 구성을 가지고 있기 때문에 인위적으로 만든 식별자 | 주문 엔티티의 주문 번호 |
> 식별자 도출 기준
- 비즈니스에서 자주 이용되는 속성을 주 식별자로 지정함
- 명칭, 장소와 같이 이름으로 기술되는 속성은 가능하면 주 식별자로 하지 않음.
- 주 식별자를 복합 식별자로 할 경우 지나치게 많은 속성이 포함되지 않도록 함.
> 과도한 복합 식별자 지양 예시
SELECT 계약금
FROM 접수
WHERE 접수.접수일자 = '20231004'
AND 접수.관할부서 = '1001'
AND 접수.입력자사번 = 'AB12345'
AND 접수.접수방법코드 = 'E'
AND 접수.신청인구분코드 = '01'
AND 접수.신청인주민번호 = '7007171234567'
AND 접수.신청횟수 = '1'- 접수 엔티티를 식별자 속성의 개수가 7개인 복합식별자를 기준으로 조회하는 SQL.
- 단 1건의 데이터를 얻기 위해서 조건절의 수가 7개임. 이러한 경우 인조식별자인 접수번호 속성을 추가한다.
↳ 접수번호 = 관할부서 + 접수일자 + 일련번호
SELECT 계약금
FROM 접수
WHERE 접수.접수번호 = '1001201023'- 인조식별자를 사용함으로 데이터 모델을 간편하고 알아보기 쉽게하며 SQL문 작성에서도 간단 명료하게함.
> 식별자 관계와 비식별자 관계의 결정
- 외부 식별자는 자기 자신의 엔티티에서 필요한 속성이 아니라 다른 엔티티와의 관계를 통해 자식쪽 엔티티에 생성되는 속성을 말하며, DB 생성시에 외래키 역할을 함.
- 자식 엔티티에서 부모 엔티티로부터 받은 외부식별자를 자신의 주 식별자로 이용할 것인지(식별자 관계) 부모와 연결이 되는 속성으로만 이용할 것인지(비식별자 관계)를 결정해야 함.
- 어떤 관계를 사용할지는 업무 특징, 자식 엔티티의 주 식별자 구성, SQL 작성 전략에 의해 결정됨.
> 비식별자 관계를 갖는 경우
- 자식 엔티티에서 받은 속성이 반드시 필수가 아니어도 무방하기 때문에 부모 없는 자식이 생성될 수 있는 경우가 비식별자 관계.
- 부모 엔티티의 주식별자를 자식 엔티티의 주식별자 속성으로 사용해도 되지만, 자식 엔티티에서 별도의 주식별자를 생성하는 것이 더 유리하다고 판단될 때, 비식별자 관계에 의한 외부 식별자로 표현.
> 식별자 관계로만 설정할 경우의 문제점
- 식별자 관계로만 각각의 엔티티 간의 관계를 정의한 데이터 모델은 관계가 도출될 때마다 PK 속성의 수가 지속적으로 증가하게 됨.
- SQL문 개발시 필연적으로 테이블 간의 조인을 하게되며, 조인에 참여하는 식별자 속성의 개수가 많을 경우 SQL문의 복잡도가 올라가면서 조인 조건을 누락하는 실수가 발생할 확률이 높아짐.
> 식별자 관계 VS 비식별자 관계
- 데이터 모델링 작업시 식별자 관계와 비식별자 관계를 취사 선택하여 연결하는 것은 높은 수준의 내공을 필요로 하는 데이터 모델링 기술.
- 식별자 관계 / 비식별자 관계 연결 고려사항
| 식별자 관계 | 비식별자 관계 | |
| 목적 | 강한 연결 관계를 표현 | 약한 연결 관계를 표현 |
| 자식 주 식별자 영향 | 부모 엔티티의 주 식별자 속성이 자식 엔티티의 주 식별자의 구성에 포함됨 | 부모 엔티티의 주 식별자 속성이 자식 엔티티의 일반 속성이 됨 |
| 연결 고려사항 | - 부모 엔티티에 종속되는 경우에 사용 - 자식 엔티티의 주 식별자 구성에 부모 엔티티의 주 식별자 속성이 필요한 경우 사용 - 부모 엔티티에게서 상속받은 주 식별자 속성을 타 엔티티에 이전이 필요한 경우 사용 |
- 부모/ 자식 간 약한 종속 관계인 경우에 사용 - 자식 엔티티의 주 식별자 구성을 독립적으로 구성할 경우에 사용 - 부모 엔티티로부터 상속받은 주 식별자 속성을 타 엔티티에게 이전하지 않도록 차단이 필요한 경우에 사용 - 부모 엔티티의 주 식별자가 NULL이 허용되는 경우에 사용 |
참고 문헌 - 이경오의 SQL+ SQLD 비밀노트 & 오라클 커뮤니티 구루비
'Database' 카테고리의 다른 글
| ROLLUP, GROUPING SETS, CUBE 간단 정리 (SQL 그룹함수) (0) | 2024.03.09 |
|---|---|
| DB 정리 - 데이터 모델과 성능 (1) | 2023.10.31 |

댓글