C로 LinkedList를 직접 구현해 보도록 하겠다.
LinkedList는 배열 자료구조의 size 고정 문제를 해결하고, 데이터 삽입/삭제의 문제도 해결되었다는 특징이 있다.
LinkedList의 대표 메서드로는 add()와 remove(), 또 특정 인덱스에 값을 갖다넣는 addAt()과 removeAt() 등이 될 것이다.
Oracle의 API에서 LinkedList가 있는 부분을 참고하여 주요 메서드들을 구현해 볼 것이다.

만들어 볼 LinkedList는 Singly LinkedList로서 Data와 다음 노드를 가리킬 포인터 노드로 이루어진 Node 구조체와 맨 첫번째 Node를 가리키는 header와 총 노드수를 나타낼 count로 이루어진 LinkedList 구조체로 구성된다.
전체적인 주요 메서드들의 동작 방식을 보겠다.
먼저 add 작업이다.
먼저 리스트를 생성 및 멤버 데이터들을 초기화 시켜준다.
list에 add(10)을 해준 상황이다. 첫 번째로 리스트에 값이 들어왔으므로 header는 새로들어온 노드를 가리키게 하고 count는 1 증가시켜준다.
그리고 이 노드는 또한 리스트의 마지막에 위치한 노드이므로 *next는 NULL을 가리키게 한다.
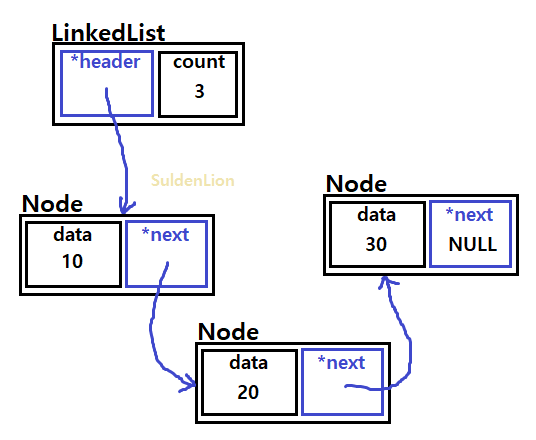
add(20)과 add(30)가 된 모습이다. 리스트의 끝 노드에 새로운 데이터를 집어넣기 위해서 해당 리스트를 traverse 해야할 필요가 있다. 그렇기 위해서는 tmp라는 포인터 노드를 하나 만들어 주고 tmp가 헤더를 가리키게 한다.
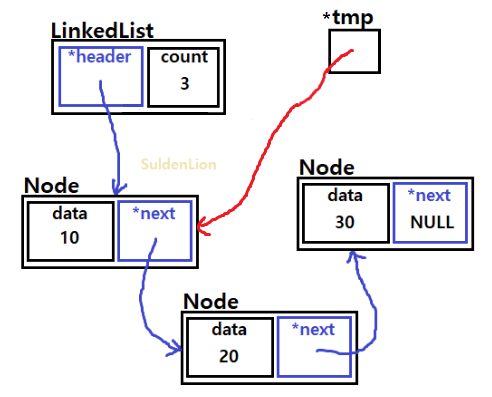
즉, 데이터 추가를 위해서 tmp는 10이 들어있는 노드부터 시작해서 30이 들어있는 마지막 노드까지 가야한다.
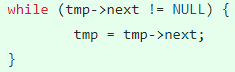
tmp->next가 NULL일 때까지 반복하면서 tmp의 참조값을 바꿔주면 마지막 노드에 도달한다.
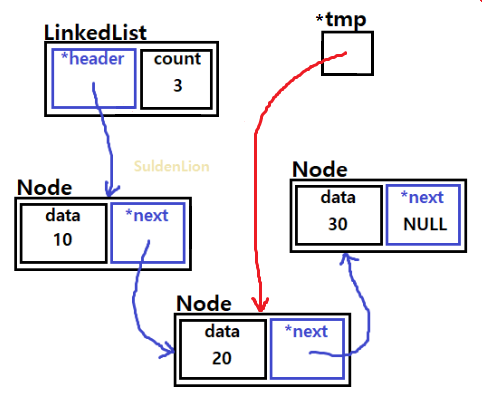
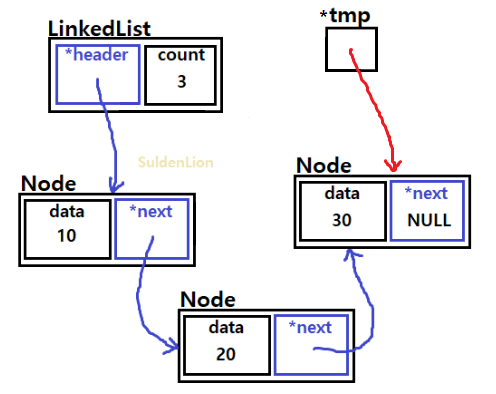
Traverse가 된 상태이다. 40의 데이터 값을 가진 새로운 노드를 추가하는 과정은 다음과 같다.
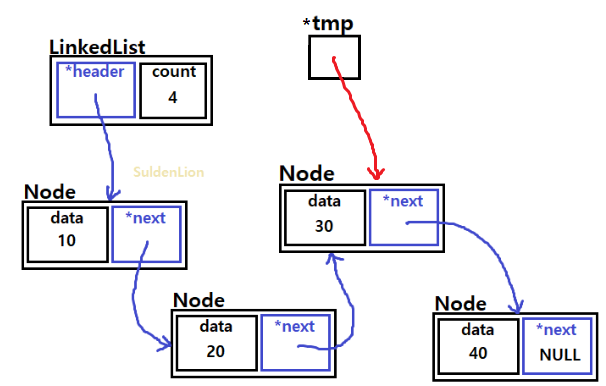
새 노드를 tmp->next가 가리키게 하고 count를 1 증가시켜주면 된다.
기본 add의 메커니즘은 대강 이렇고 리스트의 맨 앞번째에 새 노드를 넣는 addFirst, 맨 뒤에 넣는 addLast, 원하는 index에 넣는 addAt, 노드가 여러개 존재하는 다른 리스트의 모든 값들을 통째로 가져와서 추가하는 addAllAt 등의 메서드도 알아보겠다.
위의 그림에 이어서 addFirst(100)을 해보겠다.
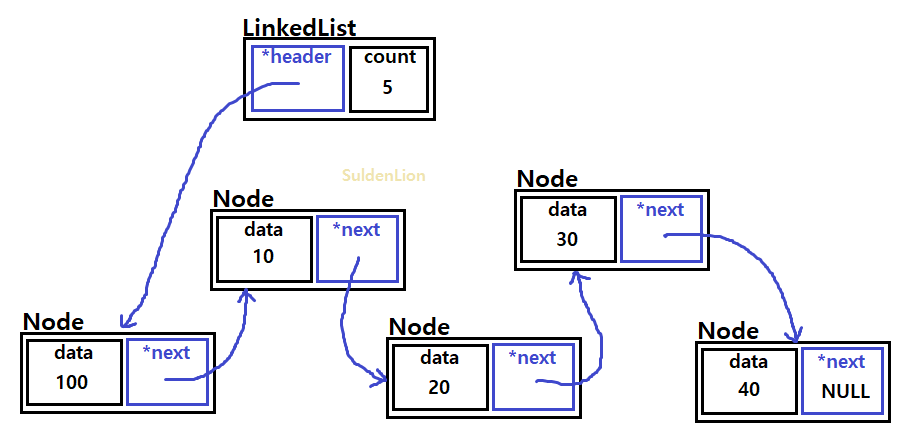
새로운 노드의 next는 헤더, 즉 10이 들어있는 노드를 가리키게 하고, 헤더는 새로운 노드를 가리키게 한다.
그 다음은 addLast인데, add와 하는 일이 같으므로 add 함수를 호출해서 처리한다.
addAt을 보겠다. addAt을 하기 위해선 값을 넣기 원하는 index와 data값이 parameter로 들어오게 된다.
위 그림 리스트의 2번째 인덱스에 200의 데이터를 가진 노드를 추가해 보겠다.
addAt(2, 200)의 결과로 10과 20의 데이터 사이에 새 노드가 추가될 것이다.
마찬가지로 해당 인덱스까지 위치를 찾아가기 위해서는 traverse 작업이 필요하다. traverse 용도의 포인터 노드 tmp를 만들어서 사용하겠다.
그 전에 Boundary condition을 정해준다. index가 0인 경우는 addFirst와 같기 때문에 addFirst를 호출해준다. index가 count를 넘어서는 경우는 잘못된 인덱스라고 Error message를 띄워주고 return 시켜주도록 하겠다.
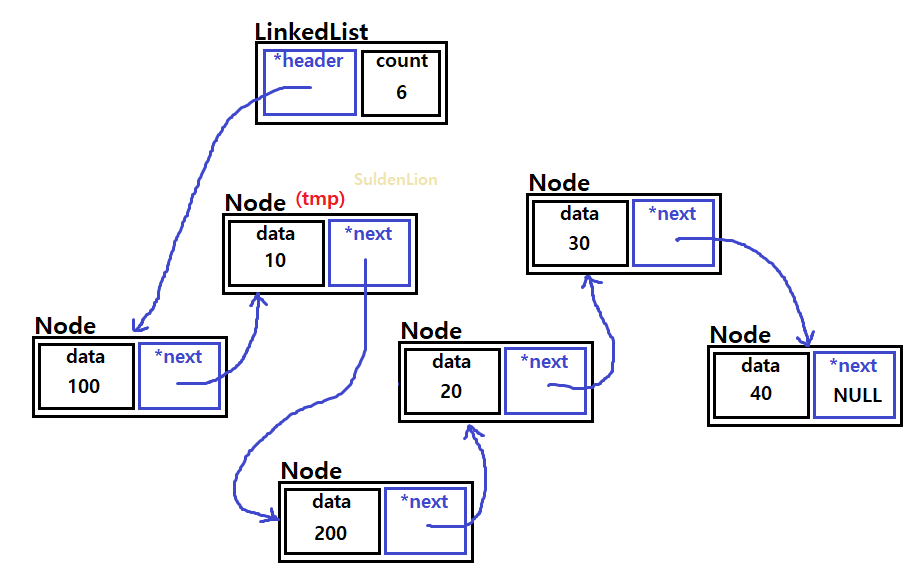
추가하고자 하는 위치의 한칸 전 노드에 tmp가 가리키도록 하고, 새로운 노드의 next가 tmp의 next (=20이 있는 노드)를 가리키게 한다. 그리고 tmp의 next에는 새로운 노드를 넣음으로써 list를 연결시킨다.
그 다음은 addAllAt() 이다. 하나의 리스트에 다른 하나의 리스트의 요소들을 추가해주는 것이다.
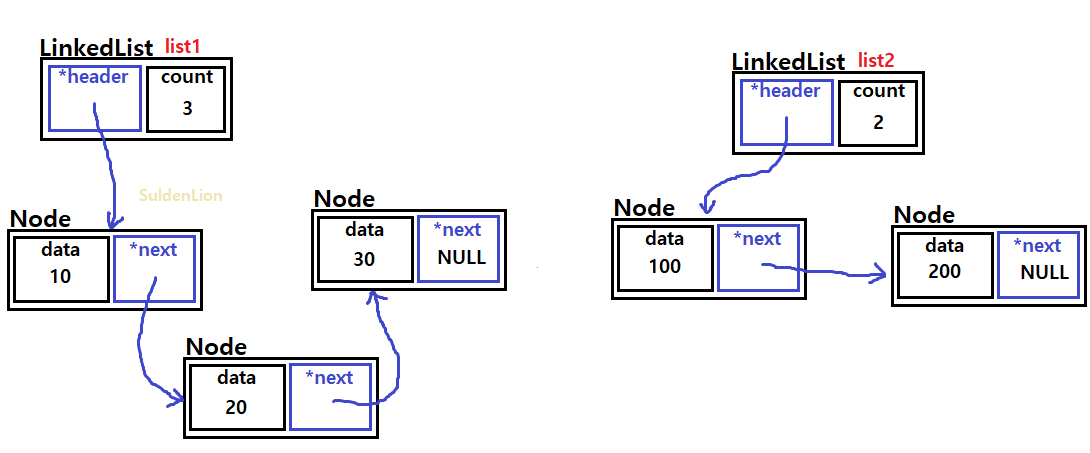
10, 20, 30의 데이터를 가진 노드들의 리스트 list1과 100, 200 의 데이터를 가진 list2가 있다고 하겠다.
list2로 하여금 list1의 2번째 인덱스(=20과 30 사이)에 addAllAt()을 해보도록 하겠다.
여기서 20이 담긴 노드의 next가 list2를 바로 참조하는 식의 shallow copy를 하여 요소를 추가하는 방법이 아닌, list2의 내용을 traverse 해가며 각 노드를 따로 list1의 index에 add하는 식의 deep copy 방법을 사용하여 만들 것이다.
바로 앞에 만든 addAt()을 이용하여 list2에서 traverse한 요소들을 list1에 끼워넣어 주면 되는데, list2의 요소들을 앞에서부터 순서대로 넣기 위해 position 변수를 하나 둔다.
position은 list1의 index가 될 부분으로 초기화 해놓고, 노드를 하나씩 거쳐갈 때마다 1씩 증가시켜준다.
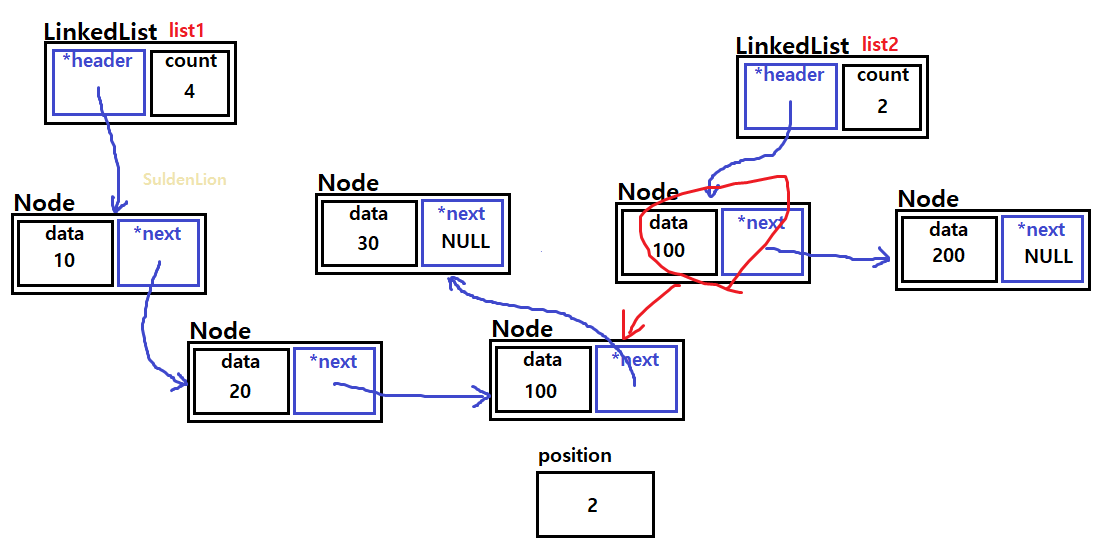
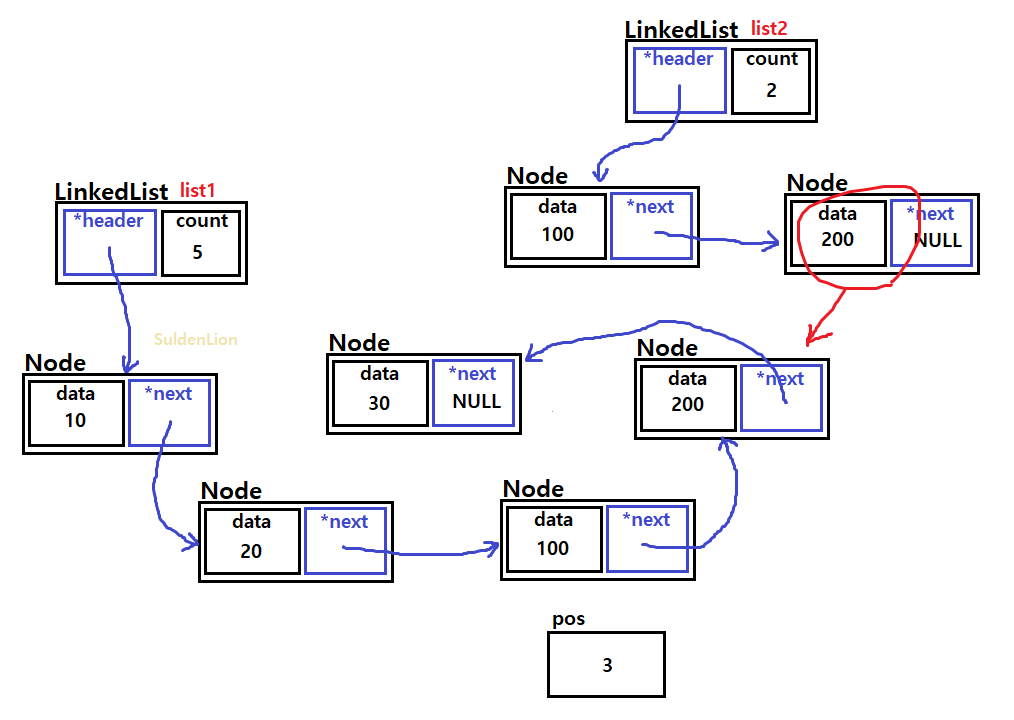
이렇게 하면 addAllAt() 메서드도 정상적으로 동작할 것이다.
그 외의 함수들을 더 보겠다.
print() 함수는 list의 data들을 traverse하여 한번에 출력해 주는 함수이다.
size() 함수는 list의 count값을 return 해준다.
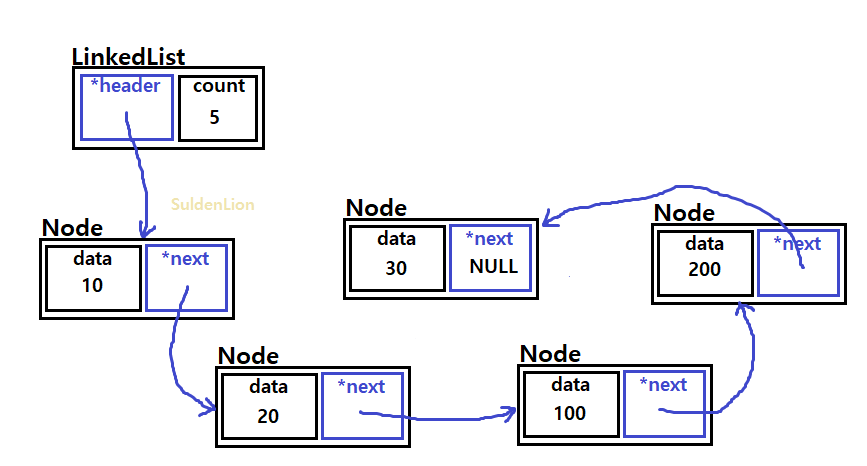
clear() 함수는 위와 같이 list가 있을 때,
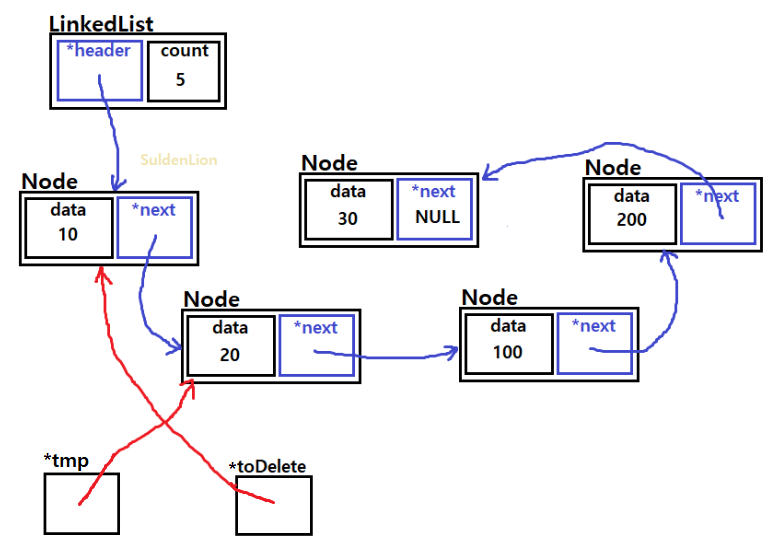
traverse를 하는 용도의 tmp노드와 tmp 노드가 지나쳐온 바로 전 노드를 가리킬 toDelete노드를 둔다.
그리고 traverse 하는 동안 그때 그때 toDelete 노드를 날려준다.
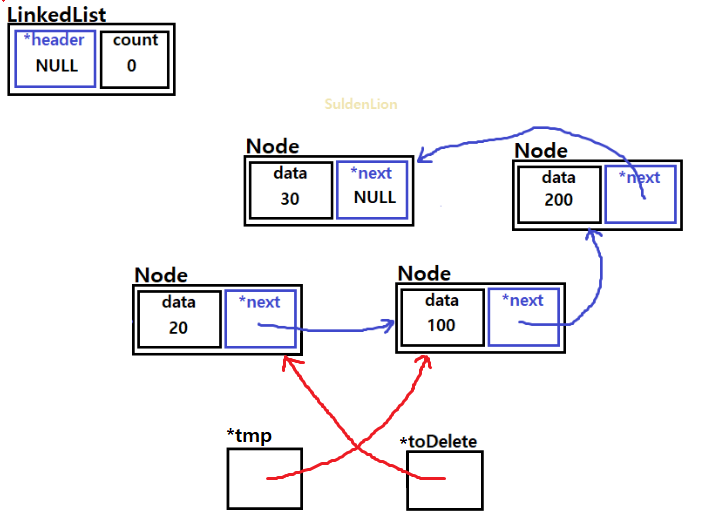
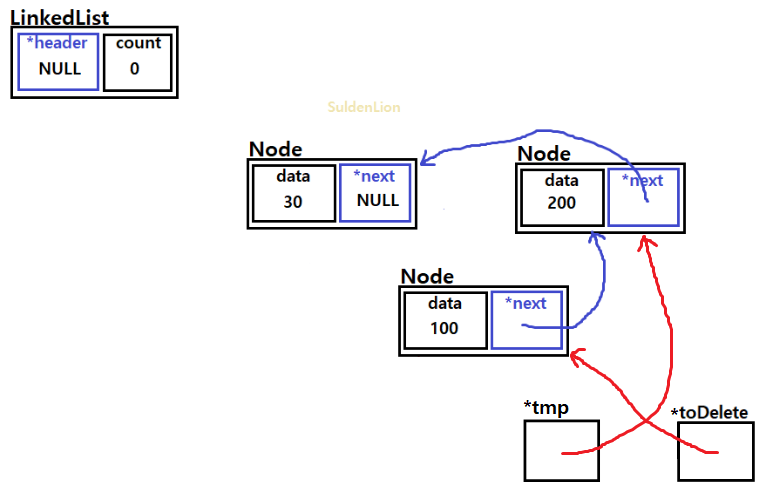
이런 식으로 참조 해가면서 노드들을 수거해 가면 된다.
list의 header에는 NULL을, count는 0으로 설정해주면 clear()가 된다.
그 다음으로 clone() 함수이다.
LinkedList *를 리턴 타입으로 두고 특정 리스트를 통째로 복사하게 할 것이다.
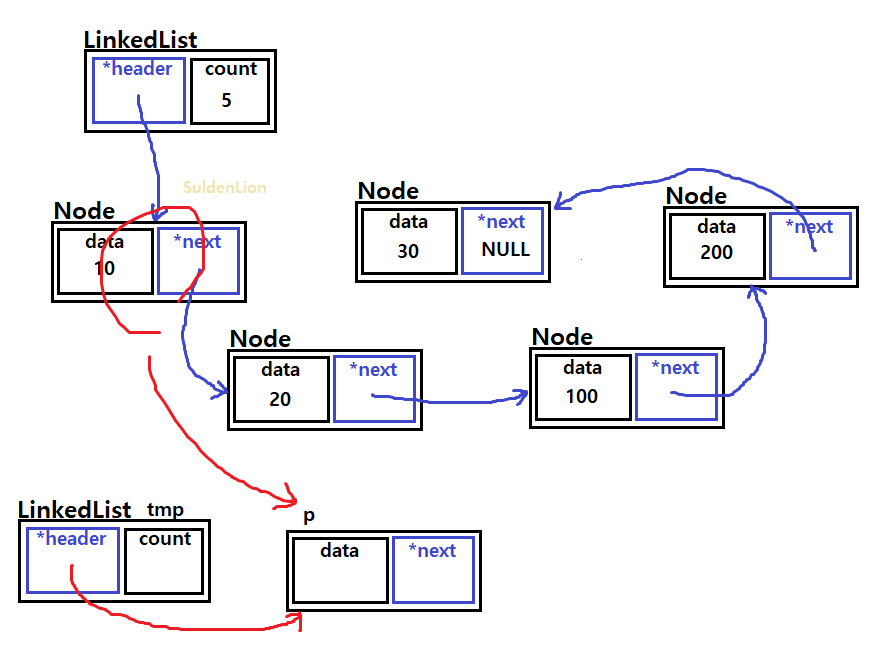
복사 후 리턴하고자 하는 list를 *tmp로 두고, 복사 될 리스트의 요소를 traverse 할 포인터 노드 p를 가져온다. p는 노드들을 순회하면서 tmp에 add작업을 해주면 될 것이다.
그리고 tmp 자체를 return시켜준다.
전체적으로 함수들이 동작하는 방식들의 결이 같다. 노드 값들을 쭉 traverse 하여 필요한 작업들을 해주면 되는 것이다.
contains() 함수는 리스트에 특정 data 값이 들어있는가를 확인하는 메서드인데, 마찬가지로 list를 traverse하면서 해당 값이 있으면 TRUE를 돌려주고, 그렇지 않다면 FALSE를 돌려주게 한다.
다음으로 get(index) 함수를 보겠다.
원하는 인덱스의 값을 찾아내어 해당 노드를 지운 후, 값을 돌려주는 함수이다. 노드를 지우는 과정은 앞서 설명한 내용과 겹치는게 많으므로 생략한다. 다만 Boundary condition에 신경을 써서 index가 0인 경우와 index가 범위를 초과할 때의 오류 처리를 확실히 해준다.
getFirst() 작업은 header의 data 값을 returnValue에 보관시켜놓고 헤더위치를 조정 및 첫번째 노드 Garbage collect 처리등의 작업을 잘 해주면 되고,
getLast() 작업도 traverse용 포인터 노드, 그리고 traverse 직전의 노드를 가리킬 포인터 노드 두개를 사용해서 Garbage 노드 처리 및 데이터 받아오는 일을 하면 된다.
> get 관련 메서드들의 내용을 착각해서 수정하겠다.
Api를 보면
값을 리턴해주고 해당 값을 지우느냐에 대해선 명시되어 있지 않다.


element()나 peek()등을 보면 does not remove 라는 식으로 적혀있는데, get은 그렇지 않아서 착오가 있었다.
get은 리스트의 내용을 건드리지 않고 해당 값만 돌려준다.
indexOf() 메서드는 parameter로 들어오는 값이 몇번 인덱스에 위치하는가를 리턴할 것인데, 이 역시 traverse 하며 값을 발견했을때 해당 인덱스를 리턴하면 된다. 주의할 점은 header가 비어있을때나 traverse가 끝났음에도 값을 찾지 못할 경우 처리를 잘 해줘야 한다.
lastIndexOf() 메서드는 특정 parameter가 중복해서 들어올 때, 해당 parameter 값이 마지막으로 발견된 인덱스를 리턴해주는 함수이다. indexOf()와 비슷하게 돌아가지만 traverse를 리스트의 끝까지 해야한다는 점은 다르다. 알고자 하는 parameter 값이 발견될 때마다 그 위치를 기록하여 최종적으로 기록된 위치값을 리턴하면 된다.
element() 함수는 데이터를 건드리지 않고 header에 위치한 데이터 값을 리턴해 오는 함수이다.
set() 함수는 list의 특정 index에 위치한 값을 원하는 값으로 바꾸는 함수이다. header가 NULL인 경우와 index가 리스트의 사이즈를 벗어나는 경우의 에러 처리를 해주고, list를 traverse 하며 해당 위치의 data 값만 바꿔주면 된다.
그 다음으로 removeData() 함수이다. remove() 라는 함수명을 쓰려 했으나 어딘가 include 받은 라이브러리에 remove()의 이름을 가진 함수가 있는건지 컴파일이 되지않아서 removeData로 이름지었다.
parameter로 정수값이 들어오는데, 이제 해당 변수가 list에서 발견되면 그 노드를 remove한다.
특수한 케이스로서, 만약에 list의 크기가 1이고, 그 하나의 data가 지우고자 하는 값이라면, header = NULL, count = 0을 해주는 식으로 처리해준다.
removeAt()은 parameter로 index 값이 들어오는데, list의 index에 위치한 값을 지워주는 함수이다. 노드를 지우는 메커니즘은 같고 traverse는 index까지만 해도 된다는 특징이 있다.
마지막으로 int *를 돌려주는 toArray() 함수이다. 리스트 객체를 배열 형태로 돌려주는 함수가 될 것이다. int 포인터 하나를 list의 사이즈 * 4bytes 한만큼 할당시켜주고, 마찬가지 list를 traverse하며 배열에 data를 하나씩 채워나가준 후, 해당 포인터를 리턴시켜준다.
이 정도로 C로 만든 LinkedList를 정리해 보도록 하겠다.
아래 소스코드는 위 전체 내용을 한 파일에 짠 것이다.
#include <stdio.h>
#include <malloc.h>
typedef struct _node {
int data;
struct _node *next;
} Node;
typedef struct _linkedList {
Node *header;
int count;
} LinkedList;
void initList(LinkedList *l)
{
l->header = NULL;
l->count = 0;
}
void addFirst(LinkedList *l, int x)
{
Node *newNode;
newNode = (Node *)malloc(sizeof(Node));
newNode->data = x;
newNode->next = l->header;
l->header = newNode;
l->count = l->count + 1;
return;
}
void add(LinkedList *l, int x)
{
Node *newNode;
Node *tmp;
newNode = (Node *)malloc(sizeof(Node));
newNode->data = x;
newNode->next = NULL;
if (l->count == 0) {
l->header = newNode;
l->count = l->count + 1;
return;
}
tmp = l->header;
while (tmp->next != NULL) {
tmp = tmp->next;
}
tmp->next = newNode;
l->count = l->count + 1;
return;
}
void addLast(LinkedList *l, int x)
{
add(l, x);
}
void addAt(LinkedList *l, int index, int x)
{
Node *tmp;
Node *newNode;
int i;
if (index == 0) {
addFirst(l, x);
return;
}
if (index > l->count) {
printf("Index out of bounds\n");
return;
}
tmp = l->header;
for (i = 1; i <= index-1; i++) {
tmp = tmp->next;
}
newNode = (Node *)malloc(sizeof(Node));
newNode->data = x;
newNode->next = tmp->next;
tmp->next = newNode;
l->count = l->count + 1;
return;
}
void addAllAt(LinkedList *l1, LinkedList *l2, int index)
{
int pos;
Node *tmp;
if (index > l1->count) {
printf("Index out of bounds\n");
return;
}
tmp = l2->header;
pos = index;
while (tmp != NULL) {
addAt(l1, pos, tmp->data);
pos = pos + 1;
tmp = tmp->next;
}
return;
}
void print(LinkedList *l)
{
Node *p = l->header;
printf("[");
while (p != NULL) {
printf("%d", p->data);
if (p->next != NULL) {
printf(", ");
}
p = p->next;
}
printf("]\n");
}
int size(LinkedList *l)
{
return l->count;
}
void clear(LinkedList *l)
{
Node *tmp;
Node *toDelete;
tmp = l->header;
while (tmp != NULL) {
toDelete = tmp;
tmp = tmp->next;
free(toDelete);
}
l->header = NULL;
l->count = 0;
}
LinkedList *clone(LinkedList *org)
{
LinkedList *tmp;
Node *p;
if (org == NULL) return NULL;
tmp = (LinkedList *)malloc(sizeof(LinkedList));
tmp->header = NULL;
tmp->count = 0;
p = org->header;
while (p != NULL) {
add(tmp, p->data);
p = p->next;
}
return tmp;
}
char* contains(LinkedList *l, int x)
{
Node *tmp;
tmp = l->header;
while (tmp != NULL) {
if (tmp->data == x) {
return "TRUE";
}
tmp = tmp->next;
}
return "FALSE";
}
int get(LinkedList *l, int index)
{
Node *tmp = l->header;
int returnValue = 0;
int i;
if (index == 0) {
returnValue = tmp->data;
return returnValue;
}
if (index >= l->count) {
printf("Cannot get element");
return -1;
}
for (i = 0; i < index; i++) {
tmp = tmp->next;
}
returnValue = tmp->data;
return returnValue;
}
int getFirst(LinkedList *l)
{
Node *tmp;
if (l->header == NULL) return -1;
return l->header->data;
}
int getLast(LinkedList *l)
{
int value;
Node *tmp;
if (l->header == NULL) {
printf("Error\n");
return -1;
}
tmp = l->header;
while (tmp->next != NULL) {
tmp = tmp->next;
}
value = tmp->data;
return value;
}
int indexOf(LinkedList *l, int x)
{
Node *tmp;
int pos = 0;
if (l->header == NULL) {
printf("Error\n");
return -1;
}
tmp = l->header;
while (tmp != NULL) {
if (tmp->data == x) return pos;
pos = pos + 1;
tmp = tmp->next;
}
printf("Cannot find element");
return -1;
}
int lastIndexOf(LinkedList *l, int x)
{
Node *tmp;
int pos = 0;
int value = -1;
if (l->header == NULL) {
printf("Error\n");
return value;
}
tmp = l->header;
while (tmp != NULL) {
if (tmp->data == x) value = pos;
tmp = tmp->next;
pos = pos + 1;
}
if (value == -1) printf("Cannot find element");
return value;
}
int element(LinkedList *l)
{
if (l->header == NULL) return -1;
return l->header->data;
}
void set(LinkedList *l, int index, int x)
{
Node *tmp;
int pos = 0;
if (l->header == NULL) {
printf("Error\n");
return;
}
if (index >= l->count) {
printf("Error\n");
return;
}
tmp = l->header;
while (tmp != NULL) {
if (pos == index) {
tmp->data = x;
return;
}
tmp = tmp->next;
pos = pos + 1;
}
}
void removeData(LinkedList *l, int x)
{
Node *tmp;
Node *follow;
if (l->header == NULL) {
printf("Error\n");
return;
}
if (l->count == 1 && l->header->data == x) {
l->header = NULL;
l->count = l->count - 1;
return;
}
tmp = l->header;
follow = l->header;
while (tmp != NULL) {
if (tmp->data == x) {
if (tmp == l->header) {
l->header = tmp->next;
l->count = l->count-1;
return;
}
follow->next = tmp->next;
free(tmp);
l->count = l->count-1;
return;
}
follow = tmp;
tmp = tmp->next;
}
printf("Cannot find element");
}
void removeAt(LinkedList *l, int index)
{
Node *tmp;
Node *follow;
int pos = 0;
if (index == 0) {
tmp = l->header;
l->header = l->header->next;
free(tmp);
l->count = l->count-1;
return;
}
if (index >= l->count) {
printf("Cannot get element");
return;
}
tmp = l->header;
follow = l->header;
for (pos = 0; pos < index; pos++) {
follow = tmp;
tmp = tmp->next;
}
follow->next = tmp->next;
l->count = l->count-1;
free(tmp);
/*
while (tmp != NULL) {
if (pos == index-1) {
follow->next = tmp->next;
l->count = l->count-1;
free(tmp);
return;
}
pos = pos + 1;
tmp = tmp->next;
}*/
}
int *toArray(LinkedList *l)
{
int *p;
Node *tmp;
int i;
if (l->count == 0) return NULL;
p = (int *)malloc(sizeof(int) * size(l));
tmp = l->header;
i = 0;
while (tmp != NULL) {
p[i] = tmp->data;
tmp = tmp->next;
i++;
}
return p;
}
main()
{
LinkedList list1;
LinkedList list2;
int *arr;
int i;
initList(&list1);
initList(&list2);
add(&list1, 10);
add(&list1, 20);
add(&list1, 30);
add(&list1, 30);
add(&list1, 30);
add(&list1, 40);
add(&list1, 50);
add(&list2, 100);
add(&list2, 200);
add(&list2, 300);
printf("list1 = ");
print(&list1);
printf("list2 = ");
print(&list2);
//printf("%d\n", get(&list1, 0));
//printf("%d\n", element(&list1));
//printf("%d\n", getFirst(&list1));
//printf("%d\n", getLast(&list1));
printf("%d\n", lastIndexOf(&list1, 30));
set(&list1, 3, 700);
//removeAt(&list1, 2);
//removeAt(&list1, 0);
removeData(&list1, 700);
printf("list1 = ");
print(&list1);
arr = toArray(&list1);
for (i = 0; i < size(&list1); i++) {
printf("%d ", arr[i]);
}
/*LinkedList list1;
LinkedList list2;
LinkedList *copied;
initList(&list1);
initList(&list2);
add(&list1, 10);
add(&list1, 20);
add(&list1, 30);
add(&list1, 40);
add(&list1, 50);
printf("list1 = ");
print(&list1);
add(&list2, 100);
add(&list2, 200);
add(&list2, 300);
printf("list2 = ");
print(&list2);
//addAllAt(&list1, &list2, 0);
addAllAt(&list1, &list2, 2);
//addAllAt(&list1, &list2, 10);
printf("list1 = ");
print(&list1);
copied = clone(&list1);
printf("copied = ");
print(copied);
printf("%s\n", contains(&list1, 300));
printf("%d\n", get(&list1, 7));
printf("%d\n", indexOf(&list1, 50));
clear(&list1);
printf("list1 = ");
print(&list1);*/
/*LinkedList list;
int n;
initList(&list);
addAt(&list, 0, 5);
addFirst(&list, 300);
add(&list, 10);
add(&list, 20);
add(&list, 30);
addFirst(&list, 100);
addFirst(&list, 200);
addLast(&list, 1000);
addLast(&list, 2000);
addAt(&list, 2, 1);
addAt(&list, 0, 2);
addAt(&list, 50, 3);
printf("%d=====\n", size(&list));
print(&list);
addAt(&list, 11, 5);
print(&list);
n = size(&list);
printf("%d\n", n);*/
}
/*
typedef struct _node {
int data;
struct _node *next;
} Node;
void print(Node *l)
{
Node *tmp = l;
printf("[");
while (tmp != NULL) {
printf("%d", tmp->data);
if (tmp->next != NULL) {
printf(", ");
}
tmp = tmp->next;
}
printf("]\n");
}
void add(Node **l, int n)
{
Node *tmp;
Node *newNode;
if (*l == NULL) {
newNode = (Node *)malloc(sizeof(Node));
newNode->data = n;
newNode->next = NULL;
*l = newNode;
return;
}
tmp = *l;
while (tmp->next != NULL) {
tmp = tmp->next;
}
newNode = (Node *)malloc(sizeof(Node));
newNode->data = n;
newNode->next = NULL;
tmp->next = newNode;
return;
}
int size(Node *l)
{
int sz = 0;
Node *tmp;
tmp = l;
while (tmp != NULL) {
tmp = tmp->next;
sz++;
}
return sz;
}
main()
{
Node *list = NULL;
int n;
n = size(list);
printf("%d\n", n);
add(&list, 7);
add(&list, 10);
add(&list, 20);
add(&list, 30);
//list = (Node *)malloc(sizeof(Node));
//list->data = 7;
//list->next = (Node *)malloc(sizeof(Node));
//list->next->data = 5;
//list->next->next = (Node *)malloc(sizeof(Node));
//list->next->next->data = 4;
//list->next->next->next = NULL;
print(list);
n = size(list);
printf("%d\n", n);
} */
위와 같은 파일을 main과 LinkedList의 헤더파일, LinkedList의 소스 파일로 분리한 코드 ↓
https://github.com/jungwu2503/Cpp/commit/5e43d46d0d650ed6bb212b7aae9439926c7a2bed
Add files via upload · jungwu2503/Cpp@5e43d46
Show file tree Showing 3 changed files with 552 additions and 0 deletions.
github.com
'Data Structure' 카테고리의 다른 글
| C++ LinkedList 만들기 (version 2 - LinkedList Template화 하기) (0) | 2023.03.25 |
|---|---|
| C++ LinkedList 만들기 (version 1) (0) | 2023.03.24 |
| C++ Stack 만들기 (version.4 - Operator overloading이란?) (0) | 2023.03.20 |
| C++ Stack 만들기 (version.3.3 - LinkedList Stack) (0) | 2023.03.19 |
| C++ Stack 만들기 (version.3.2 - LinkedList Stack) (0) | 2023.03.18 |



댓글